提升客户投诉处理效率:OCR技术自动化信息提取全攻略

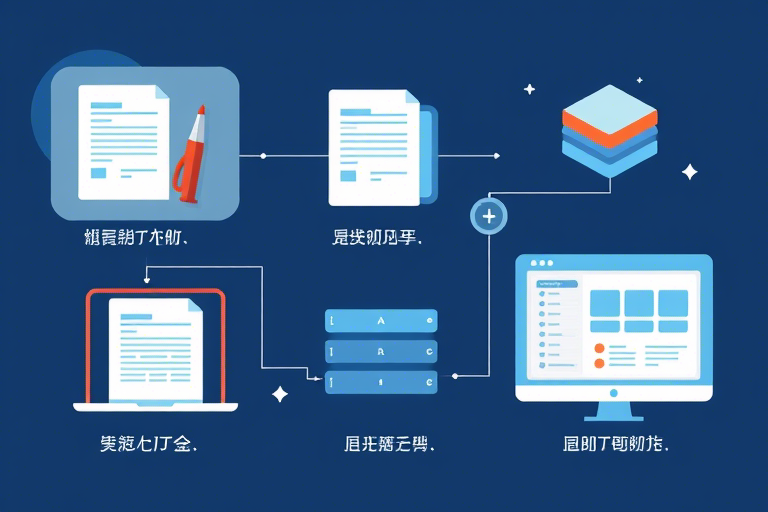
借助OCR技术自动化提取客户投诉表信息,企业能显著增强处理效率与数据准确性,此过程涉及四个核心步骤:1、甄选高效的OCR工具;2、精细的数据预处理;3、精准的表单与信息抓取;4、灵活的数据导出与储存。
OCR(Optical Character Recognition,光学字符识别)革新了文档处理领域,将纸质或图像形式的文本转化为电子数据,对于海量客户投诉表的快速处理尤为关键。本文深入解析每一步骤,引导实现自动化信息提取的高效实践。
一、甄选高效的OCR工具
首当其冲,选用合适的OCR软件是基础。理想的选择应考量:高识别精度、快速处理能力、广泛的语言支持、良好的系统集成度及合理的成本效益比。市场上,Tesseract、ABBYY FineReader及Google Cloud Vision OCR等工具广受欢迎,而蓝燕云提供的零代码平台也是集成OCR功能的优选方案,支持用户免费试用蓝燕云,体验高效的信息处理流程。
二、精细的数据预处理
预处理是提升OCR准确性的关键,包括图像去噪、二值化、合理裁剪与尺寸调整等,确保图像最佳状态进入识别环节。
三、精准的表单与信息抓取
接着,通过表单区域识别与字段级OCR识别,精准抓取投诉表中的关键信息,如姓名、联系方式及投诉详情,随后格式化输出至JSON或CSV,便于进一步处理。
四、灵活的数据导出与储存
数据处理的尾声,需将提取信息安全储存并便于访问。无论是采用数据库(MySQL、MongoDB)存储,还是生成CSV、Excel文件,或是通过API接口实现数据同步,均需依据实际业务需求定制。
总结与实战建议
综上所述,成功运用OCR技术自动提取客户投诉信息,企业需精心挑选工具、细致预处理、精准识别并合理储存数据。实践中,持续优化识别准确率与处理流程,结合蓝燕云的零代码平台,可进一步简化集成与部署,加速信息处理流程,提升客户满意度。
此外,针对常见疑问,本文提供了详尽解答,强调了从技术原理到实际应用的全链条理解,鼓励读者尝试蓝燕云的免费试用服务,亲身体验OCR技术带来的效率飞跃。

工程项目计生管理资料应该如何准备和使用?
如何有效管理房建工程隐蔽资料?
如何制定山西工程资料管理标准?

南宁工程资料管理公司如何确保项目顺利进行?

工程资料管理原则是什么?如何有效实施这些原则?

如何在校园里找到高效管理工程资料的方法?

如何有效解决工程管理资料中的难点与进行深入分析?

如何有效实施工程档案资料保密管理?

如何有效地进行长沙绿化工程资料管理?
